Forget cookies!
Client-side SQL rules. And it's rather useful: Google -- the site recently rated worst major web destination for privacy by Privacy International (rebuttal 1, rebuttal 2) -- has put out Google Gears, a browser extension which lets you use things like Google Reader in an offline mode. Functionality-wise, this seems to work nicely indeed, and I'll try it again as the next couple of flights come up -- reading blogs certainly sounds like good inflight entertainment.
The extension's key additions to today's infrastructure: You can reliably keep both Web applications and significant amounts of data locally, such as the last 2,000 blog posts, and you can talk to that data store in SQL. Applications that can use these facilities have all the abilities that cookies could ever give them, and then some more; cookies simply look boring against this.
It will be interesting to see whether (and how) the community overall takes up the tension between the functionality enabled and the privacy worries caused -- both -- by web applications' ability to link interactions much more reliably than today, and to store larger and more structured amounts of data on the client. The tension is, in fact, non-trivial: On the one hand, reliable client-side persistency clearly enables reliable linking of different interactions. On the other hand, applications could be designed to be more privacy-friendly by actually keeping information on the client, and not transmitting it to the server. If anything, this shows that discussions about privacy online can't be limited to the side-effects of this or that technology, but should actually focus on how the technology (and the data processed) are actually used.
Meanwhile, Opera's Anne van Kesteren points to Erik Arvidsson's blog, which talks about a submission of the interfaces exposed by Google Gears to WHATWG/W3C coming soon. Anne notes the relationship to related work in the HTML5 spec. (W3C's new HTML Working Group took up HTML5 as the basis for discussion with the editors and the WG going forward in May.)
PS: In terms of security models, both the HTML5 and Google Gears work rely on the same-origin policy that's well-known from cookie land.
 Our topic today, then, is the
Our topic today, then, is the 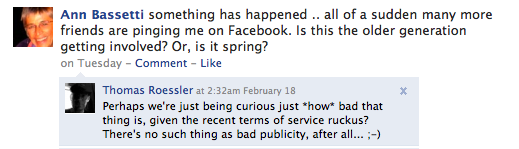 There
There  ), two points really struck me: An incredibly simple user interface, literally going out of the way when it should, making it as easy as at all possible to let me do what I'd most likely want to do -- and all that, of course, within the walled garden's fences. As an exhibit, consider the exchange between Ann Bassetti and myself up there: With Twitter, I'd have linked to it. In Facebook, it seems like I can't do that, so your only chance is going into the walled garden and trying to search for it. Second, a subtle persuasion that I'm safe and secure there. For the first couple of "friends", I'm bothered with a CAPTCHA (which goes away eventually), to "make sure I'm legit"; when I "friend" somebody who isn't in the "same network" as I am, I'm politely told that (and why!) I can't see their profile. Nothing like letting your users softly run into limits if you want to convince them that they're protected by these limits, and that you're their friend, by enforcing these limits. Remember: Facebook is your friend, it
), two points really struck me: An incredibly simple user interface, literally going out of the way when it should, making it as easy as at all possible to let me do what I'd most likely want to do -- and all that, of course, within the walled garden's fences. As an exhibit, consider the exchange between Ann Bassetti and myself up there: With Twitter, I'd have linked to it. In Facebook, it seems like I can't do that, so your only chance is going into the walled garden and trying to search for it. Second, a subtle persuasion that I'm safe and secure there. For the first couple of "friends", I'm bothered with a CAPTCHA (which goes away eventually), to "make sure I'm legit"; when I "friend" somebody who isn't in the "same network" as I am, I'm politely told that (and why!) I can't see their profile. Nothing like letting your users softly run into limits if you want to convince them that they're protected by these limits, and that you're their friend, by enforcing these limits. Remember: Facebook is your friend, it 