 The drama started with a 30min delay “due to catering”: Half of the carts for Economy class had gone missing, and even United wouldn’t launch on a 10h flight without food for the poor folks traveling in steerage. The half hour turned into two; the food was finally delivered. Pushback!
The drama started with a 30min delay “due to catering”: Half of the carts for Economy class had gone missing, and even United wouldn’t launch on a 10h flight without food for the poor folks traveling in steerage. The half hour turned into two; the food was finally delivered. Pushback!
Just a little mechanical issue, should be fixed soon, back to the gate. The mechanical problem gets fixed, “we’re about to close that door”. Alas, that’s an opportunity for some passenger to deplane. Here comes the extra hour to remove the checked baggage. The baggage door is closed, where’s the gate staff? More time flies by. Finally: Pushback!
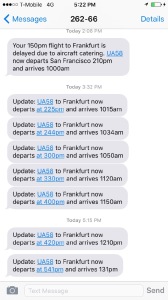
 Cheers and applause. The plane taxis, we think we’re off — alas, the flight deck crew times out, on the runway. Off to park in some corner of the taxiway. An hour later, we’re back at the gate. “They explicitly don’t know whether they’ll re-crew the plane, or whether they’re cancelling”, I text. Doors aren’t opening yet, passengers pile up in the aisle, they just want to get off the damn plane. “They’re trying to make a decision in Chicago, it’ll be 10-15min”, the pilot announces. The United app notifies me that we’ll depart at 8:19pm, or some such — then, minutes later, the flight is cancelled “due to crew rest.” Brief confusion, people deplane, queue up in the departure hall. I learn I’m going to be rebooked (along with luggage, fingers crossed) if I just go home, so that’s what I do, to an unexpected night’s sleep in my own bed. People who need accommodation are less lucky — twitter and the rumors the next day tell stories about four or six hours more in the queue, about unrest in the departure hall, screaming fits by ground staff and passengers, and calls for airport security.
Cheers and applause. The plane taxis, we think we’re off — alas, the flight deck crew times out, on the runway. Off to park in some corner of the taxiway. An hour later, we’re back at the gate. “They explicitly don’t know whether they’ll re-crew the plane, or whether they’re cancelling”, I text. Doors aren’t opening yet, passengers pile up in the aisle, they just want to get off the damn plane. “They’re trying to make a decision in Chicago, it’ll be 10-15min”, the pilot announces. The United app notifies me that we’ll depart at 8:19pm, or some such — then, minutes later, the flight is cancelled “due to crew rest.” Brief confusion, people deplane, queue up in the departure hall. I learn I’m going to be rebooked (along with luggage, fingers crossed) if I just go home, so that’s what I do, to an unexpected night’s sleep in my own bed. People who need accommodation are less lucky — twitter and the rumors the next day tell stories about four or six hours more in the queue, about unrest in the departure hall, screaming fits by ground staff and passengers, and calls for airport security.
@united I got my hotel voucher 8h after deboarding the 6h delayed UA58 of dec 21. It was a crew issue not a weather problem.
— Ali Alaoui (@AlaouiAli) December 22, 2015
Next day, we’re back. For some reason, they didn’t push all buttons on our reservations the night before, so many of us need to check in at the airport. A check-in agent tells people to go to the Lufthansa desk for “the 3pm to Frankfurt”, there is no United 3pm. “You’re wrong. There’s a special 3pm today because we didn’t fly yesterday”, I yell from far behind. “Ooops, sorry.”
 Same passengers, same plane, same crew, different flight number. There’s camaraderie: How are you doing, where did they put you up, what hotels were the parties in; the Hyatt turned off the water at 10pm; people in the lounge are boozing a little more than usual. On board, it’s “hello again” to the cabin staff — we’re all relieved that it’s finally a go. Double helpings of pre-departure champagne in business class, it’s party time and group photos on the upper deck. “We are cleared for departure.” The pilot jokes around, loud cheers. Push—
Same passengers, same plane, same crew, different flight number. There’s camaraderie: How are you doing, where did they put you up, what hotels were the parties in; the Hyatt turned off the water at 10pm; people in the lounge are boozing a little more than usual. On board, it’s “hello again” to the cabin staff — we’re all relieved that it’s finally a go. Double helpings of pre-departure champagne in business class, it’s party time and group photos on the upper deck. “We are cleared for departure.” The pilot jokes around, loud cheers. Push—
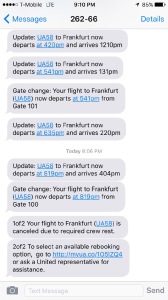
Oh wait, 30min delay due to operational reasons, says the app: Somehow, they’re only now starting to pull out the luggage that belongs to passengers who cancelled their trips or got rebooked elsewhere. “They’re telling us it’s going to take until 3:30. Having been here for 35 years, I can assure you that’s not true. It’s going to be closer to 4pm or so”, announces the pilot. Laughter — he’s good at pulling the passengers into “we’re all in this together” mode. A couple minutes later, he comes on again, more serious voice: They’ve discovered a hole in the fuselage, below the nose. The plane is not airworthy, and this can’t be repaired here and now. Crew is timing out at 6:20pm. A new aircraft and potentially new (additional?) crew will be brought in, please wait.
Back to the lounge for a coffee. I guest in the passenger ahead of me who for some reason (lack of status?) can’t get in at first, and really needs help rebooking his connecting flight to Rome. Also, why is the stub on my paper boarding pass gone? What is going on? The lounge staff (both at the door and at the reservations desk) haven’t yet heard a word, and the reservation desk lady is grumpy. While I sure hope that plane will depart, I’ve lost faith, and book a fall-back itinerary that gets me out of SFO on Virgin the next morning, and to Germany out of another US hub. I can (and later will) cancel without fee within 24h.
In the end of the day, I decide I won’t try to pull out my luggage or have UA rebook me on one of the other evening flights: Too little time to get the luggage off, over-taxed staff, and it actually looks like the new plane is materializing. Rumors there’s a new crew, so I needn’t worry about this one going illegal at 6:20pm. As I head out of the lounge, I run across the family that just wants to cancel their trip, since they were going to some remote corner in Norway that has a twice-weekly connection — which they missed.
Back on the plane, the crew’s tone has gone a little more serious: Apparently, some passengers are taking out their anger on the crew. Captain’s speaking, “I know you’re feeling frustrated and out of control. We feel the same way. This is a very senior crew, this is ruining our christmas. If you want to vent your anger, go to page 14 of the hemisphere magazine for the guy to direct it to. Here’s his email address.” Applause from the passengers. Finally: Pushback.
We taxi, wheels up at 6:30pm to loud cheers on the plane — we were supposed to be in the air a whopping 30 hours earlier.
The trip was a study in what works and what doesn’t work at United. Unfortunately, the latter appears systemic and cultural, and the former (while some of it was outstanding) spotty and individual.
The crew — unmitigated excellence, both on the flight deck and in the cabin. The captain’s mix of humor and empathy, the way he set himself and the crew apart from the airline (“I don’t believe them”), the way he went out of his way to be transparent, the way he redirected anger at entities off the plane — all that was a textbook example of a difficult negotiation done well. The cabin crew (they must have been as exasperated as the passengers were) managed to stay calm and friendly in the middle of the turmoil, and provided a basis for that negotiation.
The overall United operation — unmitigated disaster. Overtaxed and understaffed on the ground, the constantly changing departure times and promises communicated exactly one thing to the passengers: That they couldn’t believe a word that the airline was sending on official channels. Communication seemed to be as much of a mess internally as externally, or even worse: The check-in agents who weren’t told there’s another flight full of angry passengers, the lounge lady who had no clue what’s going on, the “we’re cleared for departure” when they haven’t even unloaded the excess luggage yet, the fact that Chicago was trying to make decisions about re-crewing more than an hour after the crew had expired.
Striking, too, the hole in the nose of the plane that mysteriously materialized overnight, and went “unnoticed” until we were ready to depart. It probably wasn’t the result of a rabid squirrel attack.
Would I hesitate to fly with this crew again? No.
Do I get the feeling that this airline runs an overall operation that knows how to build safety and reliability in depth, around planning, operational excellence, open communication, and a functioning culture of any kind? Hell, no.
“Hope is not a strategy” holds, in particular in as safety-critical an environment as air travel. Unfortunately, hope is all United in-flight staff and passengers alike appear to be left with.
]]>